


基本用法¶
什么是强化学习?¶
在深入了解 Gymnasium 之前,让我们先了解我们想要实现什么。强化学习就像通过试错进行教学——智能体通过尝试动作、接收反馈(奖励)并逐步改进其行为来学习。想象一下用零食训练宠物,通过练习学习骑自行车,或者通过反复玩游戏来掌握视频游戏。
关键在于我们不告诉智能体具体该做什么。相反,我们创建一个环境,让它可以在其中安全地进行实验,并从其行为的后果中学习。
为什么选择 Gymnasium?¶
无论您是想训练智能体玩游戏、控制机器人还是优化交易策略,Gymnasium 都为您提供了构建和测试想法的工具。其核心是,Gymnasium 为所有单智能体强化学习环境提供了一个 API(应用程序编程接口),并实现了常见的环境:CartPole、Pendulum、Mountain Car、Mujoco、Atari 等。本页将概述如何使用 Gymnasium 的基础知识,包括其四个关键函数:make()、Env.reset()、Env.step() 和 Env.render()。
Gymnasium 的核心是 Env,一个表示强化学习理论中马尔可夫决策过程(MDP)的高级 Python 类(注意:这不是一个完美的重构,缺少 MDP 的几个组件)。该类为用户提供了开始新情节、采取行动和可视化智能体当前状态的能力。除了 Env,还提供了 Wrapper 来帮助增强/修改环境,特别是智能体观察、奖励和所采取的行动。
初始化环境¶
在 Gymnasium 中初始化环境非常简单,可以通过 make() 函数完成
import gymnasium as gym
# Create a simple environment perfect for beginners
env = gym.make('CartPole-v1')
# The CartPole environment: balance a pole on a moving cart
# - Simple but not trivial
# - Fast training
# - Clear success/failure criteria
此函数将返回一个 Env 供用户交互。要查看可以创建的所有环境,请使用 pprint_registry()。此外,make() 还提供了许多附加参数,用于为环境指定关键字、添加更多或更少包装器等。有关更多信息,请参阅 make()。
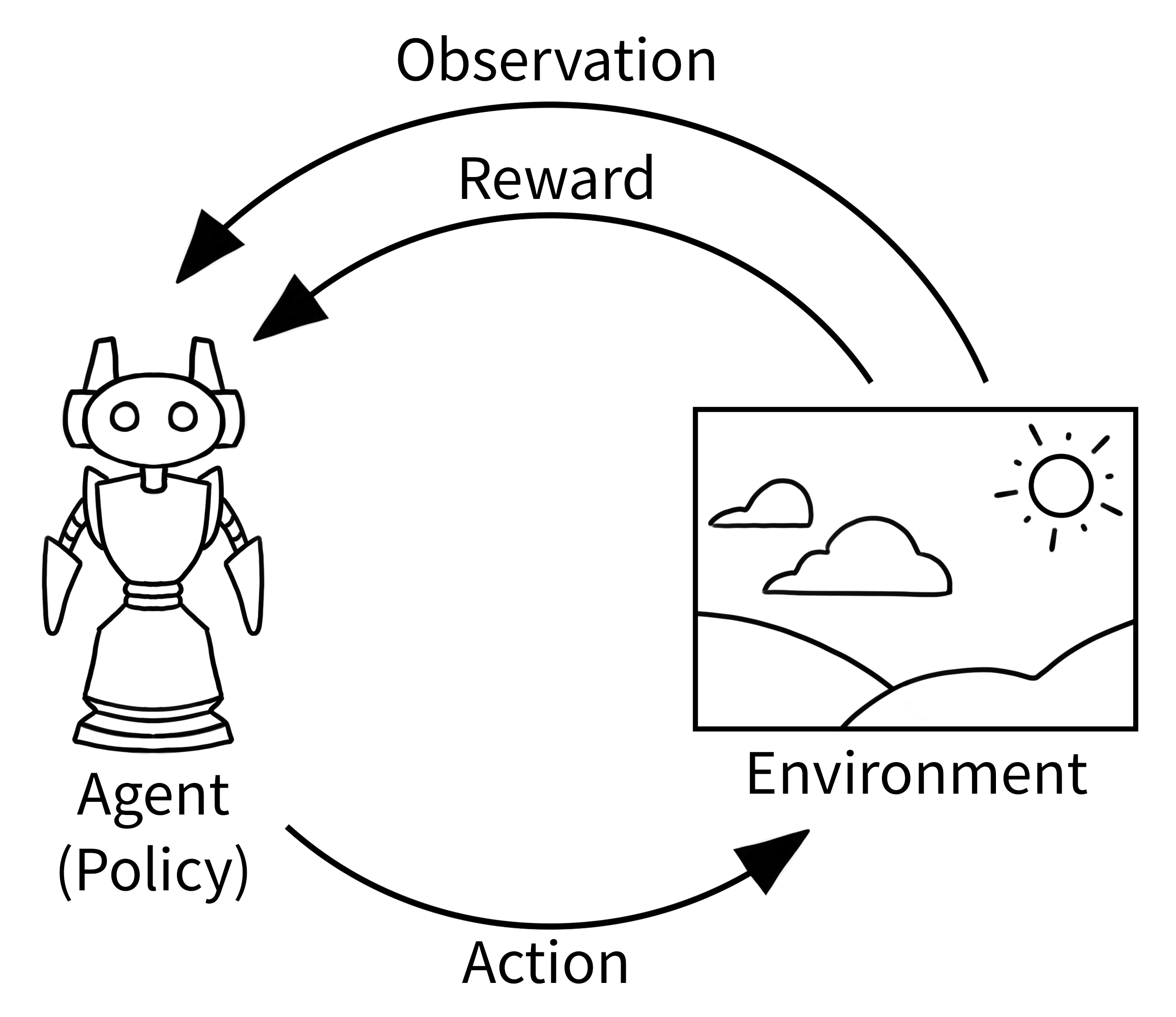
理解智能体-环境循环¶
在强化学习中,下方所示的经典“智能体-环境循环”代表了 RL 中学习的发生方式。它比初看起来要简单
智能体观察当前情况(例如看着游戏屏幕)
智能体根据所看到的内容选择一个动作(例如按下按钮)
环境响应新的情况和奖励(游戏状态改变,分数更新)
重复直到情节结束
这看起来可能很简单,但智能体就是这样学会从下棋到控制机器人再到优化业务流程的一切的。
您的第一个强化学习程序¶
让我们从一个使用 CartPole 的简单示例开始——非常适合理解基础知识
# Run `pip install "gymnasium[classic-control]"` for this example.
import gymnasium as gym
# Create our training environment - a cart with a pole that needs balancing
env = gym.make("CartPole-v1", render_mode="human")
# Reset environment to start a new episode
observation, info = env.reset()
# observation: what the agent can "see" - cart position, velocity, pole angle, etc.
# info: extra debugging information (usually not needed for basic learning)
print(f"Starting observation: {observation}")
# Example output: [ 0.01234567 -0.00987654 0.02345678 0.01456789]
# [cart_position, cart_velocity, pole_angle, pole_angular_velocity]
episode_over = False
total_reward = 0
while not episode_over:
# Choose an action: 0 = push cart left, 1 = push cart right
action = env.action_space.sample() # Random action for now - real agents will be smarter!
# Take the action and see what happens
observation, reward, terminated, truncated, info = env.step(action)
# reward: +1 for each step the pole stays upright
# terminated: True if pole falls too far (agent failed)
# truncated: True if we hit the time limit (500 steps)
total_reward += reward
episode_over = terminated or truncated
print(f"Episode finished! Total reward: {total_reward}")
env.close()
您应该看到什么:一个窗口打开,显示一个带杆的推车。推车随机左右移动,杆最终会倒下。这是预期的——智能体正在随机行动!
逐步解释代码¶
首先,使用 make() 创建一个环境,并带有一个可选的 "render_mode" 参数,该参数指定环境应如何可视化。有关不同渲染模式的详细信息,请参阅 Env.render()。渲染模式决定您看到的是可视化窗口(“human”)、获取图像数组(“rgb_array”),还是无视觉运行(None - 训练最快)。
初始化环境后,我们 Env.reset() 环境以获取第一个观察以及附加信息。这就像开始一个新游戏或新情节。要使用特定随机种子或选项初始化环境(有关可能的值,请参阅环境文档),请使用 reset() 的 seed 或 options 参数。
由于我们希望智能体-环境循环继续进行直到环境结束(这发生在未知数量的时间步中),我们将 episode_over 定义为一个变量来控制我们的 while 循环。
接下来,智能体在环境中执行一个动作。Env.step() 执行选定的动作(在我们的示例中,使用 env.action_space.sample() 随机选择动作)来更新环境。这个动作可以想象成移动机器人、按下游戏控制器上的按钮或做出交易决策。结果,智能体从更新后的环境接收到新的观察,以及采取动作的奖励。这个奖励对于好的动作(例如成功平衡杆)可能是正面的,对于坏的动作(例如让杆倒下)可能是负面的。这种动作-观察的交换被称为一个时间步。
然而,经过一些时间步后,环境可能会结束——这被称为终止状态。例如,机器人可能已经坠毁,或成功完成了任务,或者我们可能希望在固定数量的时间步后停止。在 Gymnasium 中,如果环境因任务完成或失败而终止,则 step() 会返回 terminated=True。如果我们希望环境在固定数量的时间步后结束(例如时间限制),环境会发出 truncated=True 信号。如果 terminated 或 truncated 中的任何一个为 True,我们就结束这一情节。在大多数情况下,您会希望使用 env.reset() 重新启动环境以开始新的情节。
动作空间和观察空间¶
每个环境都通过 action_space 和 observation_space 属性指定有效动作和观察的格式。这有助于了解环境的预期输入和输出,因为所有有效动作和观察都应包含在各自的空间内。在上面的示例中,我们通过 env.action_space.sample() 采样随机动作,而不是使用将观察映射到动作的智能代理策略(这就是您将要学习构建的内容)。
理解这些空间对于构建智能体至关重要: - 动作空间:您的智能体能做什么?(离散选择、连续值等) - 观察空间:您的智能体能看到什么?(图像、数字、结构化数据等)
重要的是,Env.action_space 和 Env.observation_space 都是 Space 的实例,这是一个提供关键函数 Space.contains() 和 Space.sample() 的高级 Python 类。Gymnasium 支持多种空间
Box:描述具有任何 n 维形状的上限和下限的有界空间(如连续控制或图像像素)。Discrete:描述一个离散空间,其中{0, 1, ..., n-1}是可能的值(如按钮按下或菜单选择)。MultiBinary:描述任何 n 维形状的二进制空间(如多个开关)。MultiDiscrete:由一系列Discrete动作空间组成,每个元素中有不同数量的动作。Text:描述一个具有最小和最大长度的字符串空间。Dict:描述一个更简单空间字典(如您稍后将看到的 GridWorld 示例)。Tuple:描述一个简单空间的元组。Graph:描述一个具有相互连接的节点和边的数学图(网络)。Sequence:描述可变长度的简单空间元素。
让我们看一些例子
import gymnasium as gym
# Discrete action space (button presses)
env = gym.make("CartPole-v1")
print(f"Action space: {env.action_space}") # Discrete(2) - left or right
print(f"Sample action: {env.action_space.sample()}") # 0 or 1
# Box observation space (continuous values)
print(f"Observation space: {env.observation_space}") # Box with 4 values
# Box([-4.8, -inf, -0.418, -inf], [4.8, inf, 0.418, inf])
print(f"Sample observation: {env.observation_space.sample()}") # Random valid observation
修改环境¶
包装器是一种修改现有环境而无需直接更改底层代码的便捷方式。将包装器视为过滤器或修改器,它们改变您与环境交互的方式。使用包装器可以避免重复代码,并使您的环境更具模块化。包装器还可以链接以组合其效果。
大多数通过 gymnasium.make() 创建的环境将默认被 TimeLimit(在最大步数后停止情节)、OrderEnforcing(确保正确的重置/步进顺序)和 PassiveEnvChecker(验证您的环境使用)包装。
要包装环境,您首先初始化一个基础环境,然后将其连同可选参数传递给包装器的构造函数
>>> import gymnasium as gym
>>> from gymnasium.wrappers import FlattenObservation
>>> # Start with a complex observation space
>>> env = gym.make("CarRacing-v3")
>>> env.observation_space.shape
(96, 96, 3) # 96x96 RGB image
>>> # Wrap it to flatten the observation into a 1D array
>>> wrapped_env = FlattenObservation(env)
>>> wrapped_env.observation_space.shape
(27648,) # All pixels in a single array
>>> # This makes it easier to use with some algorithms that expect 1D input
初学者认为有用的常见包装器
TimeLimit:如果超过最大时间步数,则发出截断信号(防止无限情节)。ClipAction:将传递给step的任何动作裁剪,以确保其在有效动作空间内。RescaleAction:将动作重新缩放到不同的范围(对于输出动作在 [-1, 1] 而环境需要 [0, 10] 的算法很有用)。TimeAwareObservation:将当前时间步的信息添加到观察中(有时有助于学习)。
有关 Gymnasium 中已实现包装器的完整列表,请参阅包装器。
如果您有一个被包装的环境,并且想要访问所有包装层下面的原始环境(以便手动调用函数或更改某些底层方面),您可以使用 unwrapped 属性。如果环境已经是基础环境,unwrapped 只会返回其自身。
>>> wrapped_env
<FlattenObservation<TimeLimit<OrderEnforcing<PassiveEnvChecker<CarRacing<CarRacing-v3>>>>>>
>>> wrapped_env.unwrapped
<gymnasium.envs.box2d.car_racing.CarRacing object at 0x7f04efcb8850>
初学者常见问题¶
智能体行为
智能体随机表现:使用
env.action_space.sample()时这是预期的!真正的学习发生在您用智能策略替换它时情节立即结束:检查您是否在情节之间正确处理了重置
常见代码错误
# ❌ Wrong - forgetting to reset
env = gym.make("CartPole-v1")
obs, reward, terminated, truncated, info = env.step(action) # Error!
# ✅ Correct - always reset first
env = gym.make("CartPole-v1")
obs, info = env.reset() # Start properly
obs, reward, terminated, truncated, info = env.step(action) # Now this works
下一步¶
现在您已经了解了基础知识,您可以
训练一个真正的智能体 - 用智能取代随机动作
创建自定义环境 - 构建您自己的强化学习问题
录制智能体行为 - 保存训练视频和数据
加速训练 - 使用矢量化环境和其他优化