


Hopper¶

该环境属于 Mujoco 环境,其中包含有关该环境的一般信息。
动作空间 |
|
观测空间 |
|
导入 |
|
描述¶
该环境基于 Erez、Tassa 和 Todorov 在 “Infinite Horizon Model Predictive Control for Nonlinear Periodic Tasks” 中提出的工作。该环境旨在与经典控制环境相比,增加独立状态和控制变量的数量。Hopper 是一个二维的单腿人形,由四个主要身体部分组成——顶部的躯干、中间的大腿、底部的腿,以及一个承载整个身体的单脚。目标是通过对连接四个身体部分的三个铰链施加扭矩,使其向前(向右)跳动。
动作空间¶
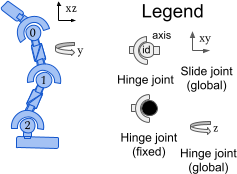
动作空间是一个 Box(-1, 1, (3,), float32)。一个动作代表施加在铰链关节上的扭矩。
编号 |
动作 |
最小控制量 |
最大控制量 |
名称 (在对应的 XML 文件中) |
关节 |
类型 (单位) |
|---|---|---|---|---|---|---|
0 |
施加在大腿转子上的扭矩 |
-1 |
1 |
thigh_joint |
铰链 |
扭矩 (N m) |
1 |
施加在腿部转子上的扭矩 |
-1 |
1 |
leg_joint |
铰链 |
扭矩 (N m) |
2 |
施加在脚部转子上的扭矩 |
-1 |
1 |
foot_joint |
铰链 |
扭矩 (N m) |
观测空间¶
观测空间由以下部分(按顺序)组成:
qpos(默认 5 个元素): 机器人身体部位的位置值。
qvel(6 个元素): 这些单独身体部位的速度(它们的导数)。
默认情况下,观测不包括机器人的 x 坐标 (rootx)。在构建时通过传入 exclude_current_positions_from_observation=False 可以将其包含在内。在这种情况下,观测空间将是 Box(-Inf, Inf, (12,), float64),其中第一个观测元素是机器人的 x 坐标。无论 exclude_current_positions_from_observation 设置为 True 还是 False,x 和 y 坐标都会通过 info 返回,键分别为 "x_position" 和 "y_position"。
然而,默认情况下,观测空间是 Box(-Inf, Inf, (11,), float64),其中元素如下:
编号 |
观测 |
最小值 |
最大值 |
名称 (在对应的 XML 文件中) |
关节 |
类型 (单位) |
|---|---|---|---|---|---|---|
0 |
躯干的 z 坐标(Hopper 的高度) |
-Inf |
Inf |
rootz |
滑动 |
位置 (m) |
1 |
躯干角度 |
-Inf |
Inf |
rooty |
铰链 |
角度 (rad) |
2 |
大腿关节角度 |
-Inf |
Inf |
thigh_joint |
铰链 |
角度 (rad) |
3 |
腿部关节角度 |
-Inf |
Inf |
leg_joint |
铰链 |
角度 (rad) |
4 |
脚部关节角度 |
-Inf |
Inf |
foot_joint |
铰链 |
角度 (rad) |
5 |
躯干 x 坐标的速度 |
-Inf |
Inf |
rootx |
滑动 |
速度 (m/s) |
6 |
躯干 z 坐标(高度)的速度 |
-Inf |
Inf |
rootz |
滑动 |
速度 (m/s) |
7 |
躯干角度的角速度 |
-Inf |
Inf |
rooty |
铰链 |
角速度 (rad/s) |
8 |
大腿铰链的角速度 |
-Inf |
Inf |
thigh_joint |
铰链 |
角速度 (rad/s) |
9 |
腿部铰链的角速度 |
-Inf |
Inf |
leg_joint |
铰链 |
角速度 (rad/s) |
10 |
脚部铰链的角速度 |
-Inf |
Inf |
foot_joint |
铰链 |
角速度 (rad/s) |
已排除 |
躯干的 x 坐标 |
-Inf |
Inf |
rootx |
滑动 |
位置 (m) |
奖励¶
总奖励为:reward = healthy_reward + forward_reward - ctrl_cost。
healthy_reward:每当 Hopper 健康时(参见“回合结束”部分中的定义),它会获得一个固定值
healthy_reward(默认为 \(1\))的奖励。forward_reward:一个向前移动的奖励,如果 Hopper 向前移动(在正 \(x\) 方向 / 向右方向),这个奖励将是正的。\(w_{forward} \times \frac{dx}{dt}\),其中 \(dx\) 是“躯干”的位移(\(x_{after-action} - x_{before-action}\)),\(dt\) 是动作之间的时间,这取决于
frame_skip参数(默认为 \(4\)),以及frametime为 \(0.002\)——所以默认为 \(dt = 4 \times 0.002 = 0.008\),\(w_{forward}\) 是forward_reward_weight(默认为 \(1\))。ctrl_cost:一个负奖励,用于惩罚 Hopper 采取过大的动作。\(w_{control} \times \|action\|_2^2\),其中 \(w_{control}\) 是
ctrl_cost_weight(默认为 \(10^{-3}\))。
info 包含各个奖励项。
起始状态¶
初始位置状态是 \([0, 1.25, 0, 0, 0, 0] + \mathcal{U}_{[-reset\_noise\_scale \times I_{6}, reset\_noise\_scale \times I_{6}]}\)。初始速度状态是 \(\mathcal{U}_{[-reset\_noise\_scale \times I_{6}, reset\_noise\_scale \times I_{6}]}\)。
其中 \(\mathcal{U}\) 是多元均匀连续分布。
请注意,z 坐标非零,以便 Hopper 可以立即站立。
回合结束¶
终止¶
如果 terminate_when_unhealthy is True(默认值),当 Hopper 不健康时环境终止。如果发生以下任何情况,Hopper 都不健康:
observation[1:](如果exclude_current_positions_from_observation=True,否则为observation[2:])的一个元素不再包含在healthy_state_range参数(默认为 \([-100, 100]\))指定的闭区间内。hopper 的高度(如果
exclude_current_positions_from_observation=True,则为observation[0];否则为observation[1])不再包含在healthy_z_range参数(默认为 \([0.7, +\infty]\))指定的闭区间内(通常意味着它已经摔倒)。躯干的角度(如果
exclude_current_positions_from_observation=True,则为observation[1];否则为observation[2])不再包含在healthy_angle_range参数(默认为 \([-0.2, 0.2]\))指定的闭区间内。
截断¶
一个回合的默认持续时间是 1000 个时间步。
参数¶
Hopper 提供了一系列参数来修改观测空间、奖励函数、初始状态和终止条件。这些参数可以在 gymnasium.make 期间以以下方式应用:
import gymnasium as gym
env = gym.make('Hopper-v5', ctrl_cost_weight=1e-3, ....)
参数 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
str |
|
MuJoCo 模型的路径 |
|
float |
|
forward_reward 项的权重(参见 |
|
float |
|
ctrl_cost 奖励的权重(参见 |
|
float |
|
healthy_reward 奖励的权重(参见 |
|
bool |
|
如果为 |
|
tuple |
|
Hopper 被认为健康时, |
|
tuple |
|
Hopper 被认为健康时,z 坐标必须在此范围内(参见 |
|
tuple |
|
Hopper 被认为健康时,由 |
|
float |
|
初始位置和速度随机扰动的规模(参见 |
|
bool |
|
是否在观测中省略 x 坐标。排除位置可以作为一种归纳偏置,以诱导策略中与位置无关的行为(参见 |
版本历史¶
v5
最低
mujoco版本现在是 2.3.3。增加了对使用
xml_file参数的完全自定义/第三方mujoco模型的支持(以前只能对现有模型进行少量更改)。添加了
default_camera_config参数,一个用于设置mj_camera属性的字典,主要用于自定义环境。添加了
env.observation_structure,一个用于指定观测空间组成(例如qpos,qvel)的字典,对于构建 MuJoCo 环境的工具和包装器很有用。reset()返回非空的info,以前返回的是空字典,新键与step()的状态信息相同。添加了
frame_skip参数,用于配置dt(step()的持续时间),默认值因环境而异,请查阅环境文档页面。修复了错误:
healthy_reward在每个步骤都给出(即使 Hopper 不健康),现在只在 Hopper 健康时给出。info["reward_survive"]已根据此更改进行更新(相关 GitHub issue)。恢复了
xml_file参数(在v4中已移除)。在
info中添加了单独的奖励项(info["reward_forward"]、info["reward_ctrl"]、info["reward_survive"])。添加了
info["z_distance_from_origin"],它等于“躯干”身体与其初始位置的垂直距离。
v4: 所有 MuJoCo 环境现在都使用 mujoco >= 2.1.3 中的 MuJoCo 绑定。
v3: 支持
gymnasium.make的 kwargs,例如xml_file、ctrl_cost_weight、reset_noise_scale等。RGB 渲染来自跟踪摄像机(因此智能体不会跑出屏幕)。移至 gymnasium-robotics repo。v2: 所有连续控制环境现在都使用 mujoco-py >= 1.50。移至 gymnasium-robotics repo。
v1: 基于机器人的任务的最大时间步提高到 1000。向环境添加了 reward_threshold。
v0: 初始版本发布。